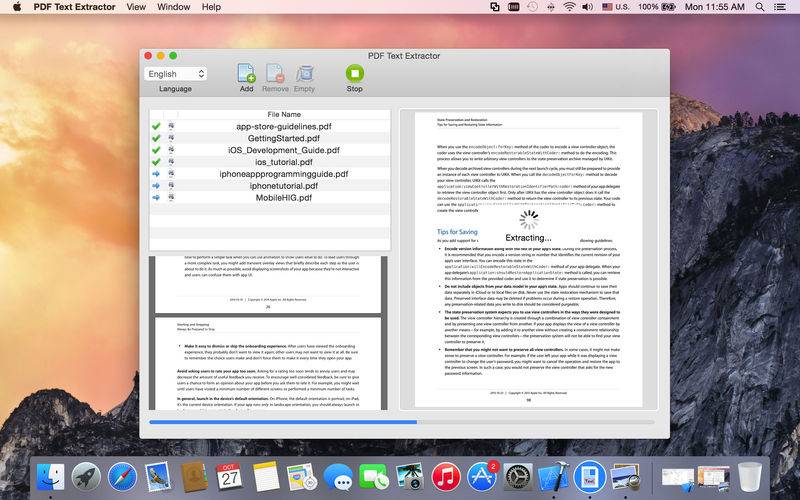
PDF Text Extractor is a utility designed to extract text from PDF files with ORC and scanned images into editable text. PDF Text Extractor can help you easily recognize text and characters from documents images. PDF Text Extractor supports 40 recognition languages. you can edit the processed text in a Word document or other document editor.
Key Features:
Convert image text content to editable text.
With PDF Text Extractor, you can easily get and use the text information of image pdf document.
OCR function
When you get scanned document and save it as pdf file, you can use PDF Text Extractor’s OCR function to recognize the text content;
Easy to use
Easy-to-use interface, you can extract text in few clicks.
Supports wide range languages.
PDF Text Extractor can extract image text about 10 languages, including English, French, German, Italian, Swedish, Russian, Polish, Dutch, Spanish, Portuguese, Japanese, Chinese.